Phân tích dữ liệu là một giai đoạn then chốt trong quá trình thực hiện các đề tài nghiên cứu, đặc biệt là đối với luận văn thạc sĩ hay cao học. Việc sử dụng phần mềm thống kê chuyên dụng như SPSS (Statistical Package for the Social Sciences) giúp biến những con số thô thành thông tin có ý nghĩa, hỗ trợ việc kiểm định giả thuyết và đưa ra kết luận khoa học. Bài viết này của Nhà Thiếu Nhi Quận 7, với chuyên môn trong việc cung cấp thông tin hữu ích, sẽ tóm tắt một quy trình phân tích dữ liệu SPSS tiêu chuẩn thường được áp dụng cho các nghiên cứu định lượng trong lĩnh vực khoa học xã hội và kinh doanh. Các bạn đang học cao học hoặc chuẩn bị thực hiện đề tài có thể tham khảo quy trình phân tích SPSS này để xây dựng sườn bài và trình bày kết quả nghiên cứu của mình.
Một quy trình phân tích dữ liệu SPSS cơ bản cho luận văn thạc sĩ thường bao gồm 6 bước kiểm định chính, giúp đảm bảo tính khoa học và độ tin cậy của kết quả nghiên cứu:
- Thống kê mô tả (tần số và trung bình)
- Kiểm định độ tin cậy thang đo Cronbach’s Alpha
- Phân tích nhân tố khám phá EFA
- Phân tích tương quan tuyến tính Pearson
- Phân tích hồi quy tuyến tính bội
- Phân tích khác biệt trung bình (T Test/ One-way ANOVA)
Alt: Hình minh họa quy trình phân tích dữ liệu SPSS cho luận văn cao học với 6 bước cơ bản
1. Thống Kê Mô Tả (Descriptive Statistics)
Trong quy trình phân tích SPSS, thống kê mô tả là bước đầu tiên và cơ bản nhất. Nhóm công cụ này được sử dụng để tóm tắt và mô tả các đặc điểm chính của tập dữ liệu nghiên cứu. Các chỉ số thường gặp bao gồm giá trị trung bình (mean), độ lệch chuẩn (standard deviation), tần suất (frequency), phần trăm (percentage), giá trị nhỏ nhất (minimum), giá trị lớn nhất (maximum), phạm vi (range), mode, trung vị (median),… Khi thực hiện luận văn, hai loại thống kê mô tả được sử dụng phổ biến nhất là thống kê tần số và thống kê trung bình.
a. Thống Kê Tần Số (Frequency)
Thống kê tần số giúp người nghiên cứu có cái nhìn tổng quát về đặc điểm của mẫu khảo sát và kết quả thu được. Ví dụ, bạn có thể biết được tỷ lệ nam/nữ trong mẫu, phân bố đối tượng theo địa lý (TP. Hồ Chí Minh, Hà Nội, tỉnh khác), theo độ tuổi, nghề nghiệp,…
Kết quả của thống kê tần số trên SPSS thường hiển thị dưới dạng bảng tần số (frequency table), tỷ trọng (percentage) và biểu đồ (hình tròn hoặc cột) tương ứng.
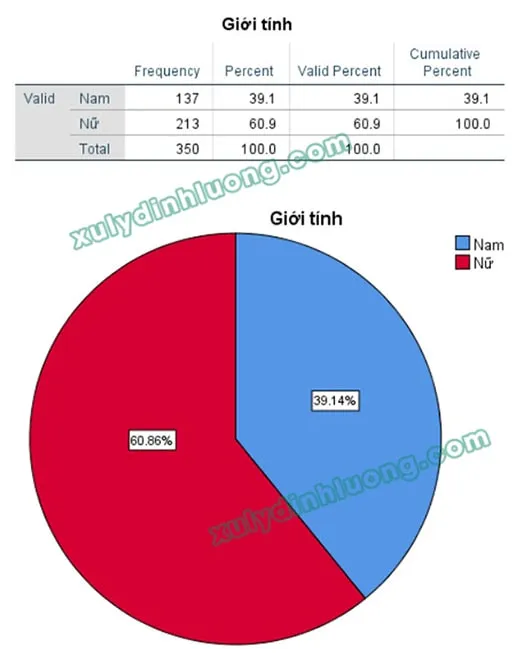 thống kê tần số spssAlt: Bảng kết quả thống kê tần số trên phần mềm SPSS hiển thị tần số và tỷ lệ phần trăm
thống kê tần số spssAlt: Bảng kết quả thống kê tần số trên phần mềm SPSS hiển thị tần số và tỷ lệ phần trăm
Dựa vào bảng tần số và tỷ trọng, chúng ta mô tả chi tiết đặc điểm của đối tượng khảo sát. Việc phân tích này giúp đánh giá xem nhóm đối tượng thu thập có phù hợp với mục tiêu nghiên cứu của đề tài hay không. Nếu phát hiện sự chênh lệch lớn (ví dụ: nghiên cứu về giới trẻ nhưng mẫu khảo sát lại phần lớn là người lớn tuổi), cần xem xét điều chỉnh mẫu nghiên cứu bằng cách loại bỏ hoặc bổ sung đáp viên để đảm bảo tính đại diện.
b. Thống Kê Trung Bình (Descriptives)
Trong khi thống kê tần số mạnh về mô tả đặc điểm phân loại, thống kê trung bình cung cấp các giá trị tính toán tổng quát của biến định lượng như giá trị nhỏ nhất, lớn nhất, trung bình, độ lệch chuẩn.
Kết quả của thống kê trung bình trên SPSS thường là một bảng hiển thị các chỉ số Min, Max, Mean, Standard Deviation,… cho các biến được chọn.
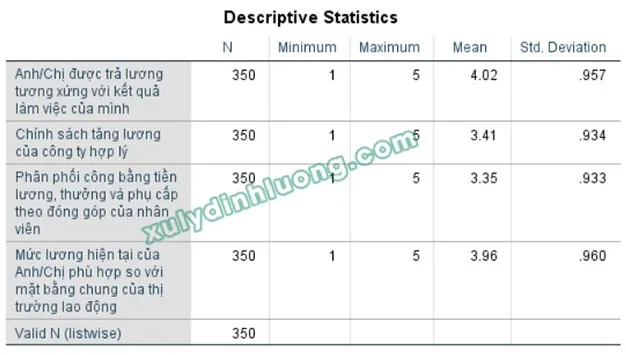 thống kê trung bình spssAlt: Bảng kết quả thống kê trung bình (Descriptives) trên phần mềm SPSS hiển thị giá trị Min, Max, Mean, Std. Deviation
thống kê trung bình spssAlt: Bảng kết quả thống kê trung bình (Descriptives) trên phần mềm SPSS hiển thị giá trị Min, Max, Mean, Std. Deviation
Kết quả thống kê trung bình giúp xác định phạm vi giá trị của biến thông qua giá trị nhỏ nhất và lớn nhất. Từ đó, chúng ta có thể kiểm tra dữ liệu có bất thường hay sai sót trong quá trình nhập liệu hay không (ví dụ: sử dụng thang đo 5 mức độ nhưng lại xuất hiện giá trị 0 hoặc 55). Giá trị trung bình (Mean) phản ánh mức độ tổng thể của biến. Nếu Mean gần giá trị cao nhất của thang đo (ví dụ: 4.5 trên thang 5), cho thấy yếu tố đó được đánh giá tích cực; ngược lại, nếu Mean gần giá trị thấp nhất (ví dụ: 1.8 trên thang 5), cho thấy yếu tố đó đang ở mức tiêu cực.
2. Phân Tích Độ Tin Cậy Cronbach’s Alpha
Sau khi hoàn thành bước thống kê mô tả trong quy trình phân tích SPSS, kiểm định Cronbach’s Alpha là bước quan trọng tiếp theo, đặc biệt khi sử dụng các thang đo đa mục (multi-item scales) để đo lường các khái niệm phức tạp. Mục đích của kiểm định này là đánh giá độ tin cậy nội bộ (internal consistency) của các câu hỏi dùng để đo lường cùng một khái niệm/yếu tố.
Cronbach’s Alpha giúp:
- Xem xét sự phù hợp của các câu hỏi được xây dựng để đo lường một yếu tố. Nếu câu hỏi nào không tương quan tốt với các câu hỏi khác trong cùng một thang đo (do hỏi sai, hiểu lầm…), cần loại bỏ câu hỏi đó.
- Đánh giá tổng thể bộ câu hỏi đo lường một yếu tố có đủ độ tin cậy theo tiêu chuẩn không. Nếu hệ số Cronbach’s Alpha thấp ngay cả sau khi loại bỏ các biến không phù hợp, cần xem xét lại toàn bộ thang đo hoặc loại bỏ yếu tố đó khỏi nghiên cứu.
Kết quả của phân tích Cronbach’s Alpha trên SPSS gồm hai bảng chính:
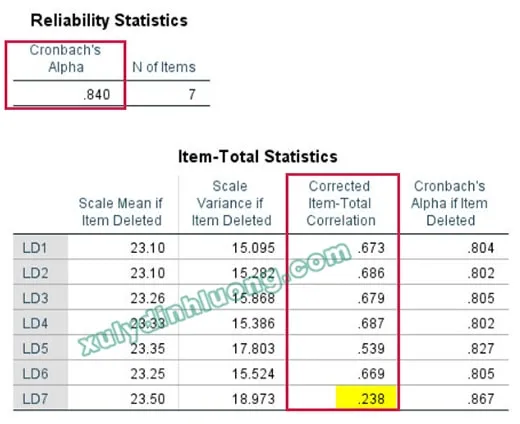 quy trình phân tích SPSS luận văn cao học – Cronbach's AlphaAlt: Bảng kết quả kiểm định Cronbach’s Alpha trong SPSS hiển thị hệ số tin cậy
quy trình phân tích SPSS luận văn cao học – Cronbach's AlphaAlt: Bảng kết quả kiểm định Cronbach’s Alpha trong SPSS hiển thị hệ số tin cậy
- Bảng Reliability Statistics chứa giá trị hệ số Cronbach’s Alpha. Giá trị này thường được chấp nhận nếu đạt từ 0.7 trở lên (tùy lĩnh vực và quy ước có thể chấp nhận từ 0.6).
- Bảng Item-Total Statistics chứa giá trị Corrected Item-Total Correlation của từng biến quan sát trong thang đo. Giá trị này cho biết mức độ tương quan giữa một câu hỏi với tổng điểm của các câu hỏi còn lại trong cùng thang đo. Một biến quan sát được coi là đáng tin cậy nếu giá trị này đạt từ 0.3 trở lên.
3. Phân Tích Nhân Tố Khám Phá EFA (Exploratory Factor Analysis)
Trong các bước chạy SPSS cho luận văn cao học, phân tích EFA có thể tùy thuộc vào tính chất của đề tài (nghiên cứu khám phá hay nghiên cứu lặp lại/kiểm định mô hình). Với các đề tài lặp lại dựa trên các thang đo đã được kiểm định trong các nghiên cứu trước, giảng viên hướng dẫn có thể bỏ qua bước EFA và đi thẳng vào phân tích tương quan, hồi quy sau Cronbach’s Alpha. Tuy nhiên, với nghiên cứu khám phá hoặc sử dụng thang đo mới, EFA là bước không thể thiếu.
Phân tích nhân tố khám phá (EFA) được sử dụng để rút gọn một tập hợp lớn các biến quan sát thành một số ít các nhân tố (factor) có ý nghĩa hơn, làm cơ sở cho các phân tích tiếp theo như tương quan, hồi quy.
EFA giúp:
- Xác định các biến quan sát đầu vào được nhóm lại thành bao nhiêu nhân tố.
- Đánh giá tính hội tụ (convergence – các biến đo lường cùng một khái niệm nhóm lại với nhau) và tính phân biệt (discrimination – các biến đo lường các khái niệm khác nhau tách biệt nhau) của các thang đo.
- Xác định các biến quan sát không tải (load) lên bất kỳ nhân tố nào hoặc tải chéo (load lên nhiều nhân tố cùng lúc) cần loại bỏ.
Kết quả của phân tích EFA trên SPSS gồm ba bảng quan trọng:
Alt: Bảng KMO and Bartlett’s Test trong phân tích EFA trên SPSS đánh giá sự phù hợp của dữ liệu
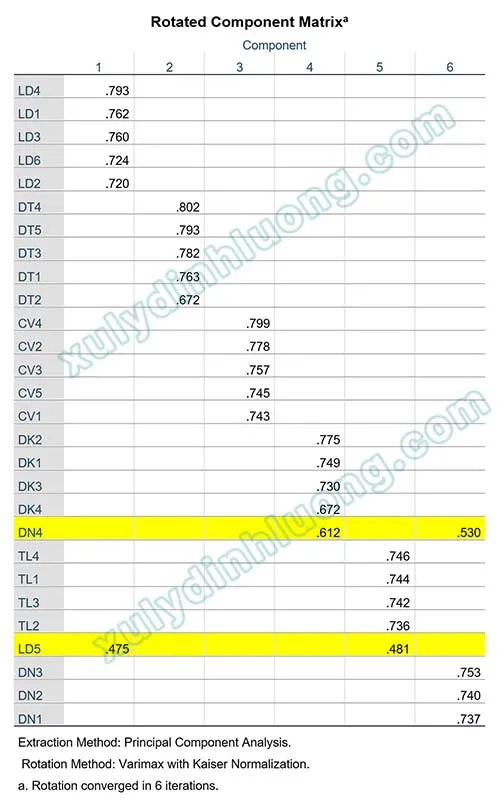 kết quả phân tích nhân tố EFA 2Alt: Bảng Total Variance Explained trong phân tích EFA trên SPSS cho biết tổng phương sai trích
kết quả phân tích nhân tố EFA 2Alt: Bảng Total Variance Explained trong phân tích EFA trên SPSS cho biết tổng phương sai trích
- Bảng KMO and Bartlett’s Test: Giá trị KMO (Kaiser-Meyer-Olkin) phải đạt từ 0.5 trở lên và Sig của kiểm định Bartlett (Sig. < 0.05) cho thấy dữ liệu phù hợp để thực hiện EFA.
- Bảng Total Variance Explained: Giá trị Cumulative % (tổng phương sai trích) nên đạt từ 50% trở lên để các nhân tố trích xuất giải thích được phần lớn biến thiên của các biến quan sát gốc.
- Bảng Rotated Component Matrix (hoặc Pattern Matrix sau phép quay): Hiển thị hệ số tải (factor loading) của các biến quan sát lên các nhân tố. Biến quan sát nên tải mạnh (hệ số > 0.5) lên một nhân tố duy nhất và tải yếu lên các nhân tố khác để đảm bảo tính hội tụ và phân biệt.
4. Phân Tích Tương Quan Pearson (Pearson Correlation)
Thường được thực hiện sau khi các thang đo đã được xác nhận độ tin cậy và tính hợp lệ (qua Cronbach’s Alpha và EFA), phân tích tương quan Pearson là một bước quan trọng trong các bước phân tích dữ liệu với SPSS. Mục đích chính là kiểm tra mối quan hệ tuyến tính giữa các cặp biến định lượng.
Trong bối cảnh luận văn sử dụng hồi quy, phân tích tương quan Pearson giúp:
- Kiểm tra mối liên hệ ban đầu giữa biến phụ thuộc và các biến độc lập. Kỳ vọng có mối tương quan có ý nghĩa thống kê (Sig. < 0.05) và hệ số tương quan đủ mạnh (tùy lĩnh vực, thường > 0.3) giữa biến độc lập và biến phụ thuộc.
- Sớm nhận diện vấn đề đa cộng tuyến (multicollinearity) khi các biến độc lập có tương quan quá mạnh với nhau (thường hệ số tương quan > 0.8). Đa cộng tuyến có thể ảnh hưởng đến kết quả phân tích hồi quy.
Kết quả của phân tích tương quan Pearson trên SPSS là một ma trận tương quan hiển thị hệ số tương quan (Pearson Correlation) và giá trị Sig. (2-tailed) giữa các cặp biến được chọn.
Alt: Bảng ma trận kết quả phân tích tương quan Pearson trên phần mềm SPSS
Kiểm tra giá trị Sig. giữa biến độc lập và biến phụ thuộc. Nếu Sig. < 0.05, có mối tương quan tuyến tính có ý nghĩa thống kê. Hệ số tương quan cho biết chiều (dương/âm) và độ mạnh của mối quan hệ. Đối với tương quan giữa các biến độc lập, kỳ vọng hệ số không quá cao để tránh đa cộng tuyến, mặc dù giá trị Sig. giữa các biến độc lập không quá quan trọng ở bước này.
5. Phân Tích Hồi Quy Tuyến Tính Bội (Multiple Linear Regression)
Phân tích hồi quy tuyến tính bội là bước phân tích quan trọng nhất trong quy trình phân tích dữ liệu SPSS cho luận văn cao học định lượng, vì đây là bước trực tiếp kiểm định các giả thuyết nghiên cứu và mô hình đề xuất. Phân tích này giúp xác định mức độ và chiều hướng tác động của một hoặc nhiều biến độc lập lên một biến phụ thuộc duy nhất.
Phân tích hồi quy giúp trả lời các câu hỏi:
- Biến độc lập nào có tác động có ý nghĩa thống kê lên biến phụ thuộc?
- Mức độ tác động (mạnh hay yếu) của từng biến độc lập là bao nhiêu?
- Chiều hướng tác động là thuận chiều hay nghịch chiều?
- Mô hình hồi quy tổng thể giải thích được bao nhiêu phần trăm sự biến thiên của biến phụ thuộc?
Kết quả của phân tích hồi quy trên SPSS gồm ba bảng chính cần phân tích:
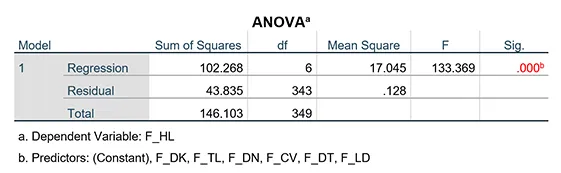 bảng ANOVA trong phân tích hồi quy SPSSAlt: Bảng ANOVA trong kết quả phân tích hồi quy trên SPSS
bảng ANOVA trong phân tích hồi quy SPSSAlt: Bảng ANOVA trong kết quả phân tích hồi quy trên SPSS
 bảng Model Summary trong hồi quy SPSSAlt: Bảng Model Summary trong kết quả phân tích hồi quy trên SPSS hiển thị R Square và R Square hiệu chỉnh
bảng Model Summary trong hồi quy SPSSAlt: Bảng Model Summary trong kết quả phân tích hồi quy trên SPSS hiển thị R Square và R Square hiệu chỉnh
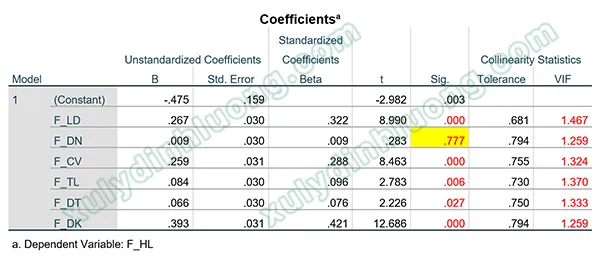 bảng Coefficients trong hồi quy SPSSAlt: Bảng Coefficients trong kết quả phân tích hồi quy trên SPSS hiển thị hệ số Beta và giá trị Sig.
bảng Coefficients trong hồi quy SPSSAlt: Bảng Coefficients trong kết quả phân tích hồi quy trên SPSS hiển thị hệ số Beta và giá trị Sig.
- Bảng ANOVA: Kiểm tra ý nghĩa thống kê của mô hình hồi quy tổng thể. Giá trị Sig. (< 0.05) cho thấy mô hình phù hợp với dữ liệu, nghĩa là ít nhất một biến độc lập có tác động lên biến phụ thuộc.
- Bảng Model Summary: Chứa giá trị R Square và Adjusted R Square. R Square cho biết tỷ lệ phần trăm biến thiên của biến phụ thuộc được giải thích bởi các biến độc lập trong mô hình. Adjusted R Square là R Square đã hiệu chỉnh, thường được dùng để so sánh các mô hình có số lượng biến độc lập khác nhau.
- Bảng Coefficients: Đây là bảng quan trọng nhất để kiểm định từng giả thuyết. Cột Sig. cho biết biến độc lập tương ứng có tác động có ý nghĩa thống kê (Sig. < 0.05) hay không. Cột B (Unstandardized Coefficients) cho biết sự thay đổi trung bình của biến phụ thuộc khi biến độc lập tăng 1 đơn vị (trong thang đo gốc). Cột Beta (Standardized Coefficients) cho biết mức độ tác động tương đối giữa các biến độc lập với biến phụ thuộc (biến nào có |Beta| lớn hơn thì tác động mạnh hơn). Dấu của hệ số B hoặc Beta (+/-) cho biết chiều hướng tác động (thuận chiều hay nghịch chiều).
6. Phân Tích Khác Biệt Trung Bình (T Test/ One-way ANOVA)
Để có cái nhìn sâu sắc hơn về sự khác biệt giữa các nhóm đối tượng, hỗ trợ cho việc đưa ra giải pháp và kiến nghị, bước thứ 6 trong quy trình xử lý dữ liệu SPSS là phân tích khác biệt trung bình. Chúng ta sử dụng các kiểm định này khi muốn so sánh giá trị trung bình của một biến định lượng giữa các nhóm được phân loại bởi một biến định tính.
Ví dụ: So sánh mức độ hài lòng về khóa học năng khiếu giữa học viên nam và nữ (biến định lượng: hài lòng; biến định tính: giới tính – 2 nhóm). Hoặc so sánh kết quả học tập (biến định lượng) giữa học viên ở các độ tuổi khác nhau (biến định tính: độ tuổi – nhiều nhóm).
Việc phân tích sự khác biệt trung bình này giúp nhận diện các nhóm đối tượng có đặc điểm khác nhau thể hiện hành vi hoặc quan điểm khác nhau đối với chỉ tiêu nghiên cứu. Từ đó, có thể đề xuất các giải pháp hoặc chương trình phù hợp cho từng nhóm cụ thể.
a. Independent Sample T Test
Kiểm định Independent-Samples T Test được sử dụng khi biến định tính chỉ có hai nhóm giá trị độc lập (ví dụ: nam/nữ, có/không, trước/sau). Kiểm định này xác định xem có sự khác biệt có ý nghĩa thống kê về giá trị trung bình của biến định lượng giữa hai nhóm này hay không.
Kết quả của Independent Sample T Test trên SPSS bao gồm bảng so sánh trung bình giữa hai nhóm và bảng kiểm định t. Giá trị Sig. trong bảng kiểm định t là thông tin cần quan tâm chính.
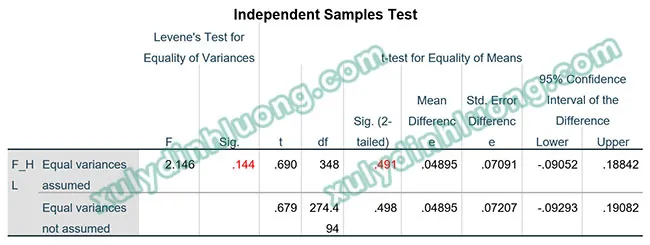 bảng Independent Samples Test trong SPSSAlt: Bảng kết quả Independent Samples Test trong SPSS so sánh trung bình giữa hai nhóm
bảng Independent Samples Test trong SPSSAlt: Bảng kết quả Independent Samples Test trong SPSS so sánh trung bình giữa hai nhóm
Nếu giá trị Sig. (2-tailed) của kiểm định t nhỏ hơn 0.05, có sự khác biệt có ý nghĩa thống kê về trung bình của biến định lượng giữa hai nhóm được so sánh.
b. One-way ANOVA
Khi biến định tính có từ ba nhóm giá trị độc lập trở lên (ví dụ: mức thu nhập: dưới 10 triệu, từ 10-20 triệu, trên 20 triệu; trình độ học vấn: cấp 3, đại học, sau đại học), chúng ta không thể sử dụng T Test. Thay vào đó, kiểm định One-Way ANOVA (ANOVA một chiều) được sử dụng để so sánh giá trị trung bình của biến định lượng giữa các nhóm này.
Kết quả của One-way ANOVA trên SPSS hiển thị bảng ANOVA. Giá trị Sig. trong bảng này là thông tin chính.
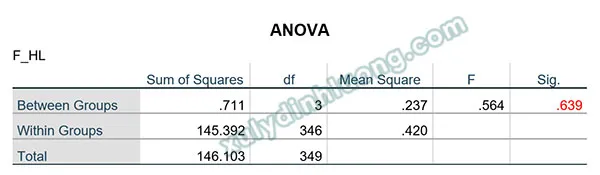 bảng ANOVA trong SPSSAlt: Bảng kết quả kiểm định ANOVA một chiều trong SPSS
bảng ANOVA trong SPSSAlt: Bảng kết quả kiểm định ANOVA một chiều trong SPSS
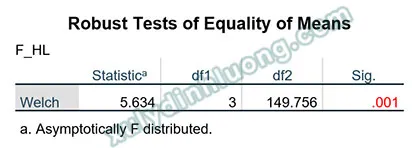 bảng Robust Tests of Equality of Means trong ANOVA SPSSAlt: Bảng kết quả kiểm định Welch trong ANOVA SPSS (sử dụng khi phương sai không đồng nhất)
bảng Robust Tests of Equality of Means trong ANOVA SPSSAlt: Bảng kết quả kiểm định Welch trong ANOVA SPSS (sử dụng khi phương sai không đồng nhất)
Nếu giá trị Sig. của kiểm định F (hoặc kiểm định Welch nếu giả định phương sai đồng nhất bị vi phạm) nhỏ hơn 0.05, có sự khác biệt có ý nghĩa thống kê về trung bình của biến định lượng giữa ít nhất một cặp nhóm trong các nhóm được so sánh. Để xác định cặp nhóm cụ thể nào có sự khác biệt, cần thực hiện thêm các kiểm định Post-Hoc (ví dụ: Tukey, LSD).
Trên đây là quy trình 6 kiểm định cơ bản thường được sử dụng khi phân tích dữ liệu SPSS cho luận văn thạc sĩ, cao học trong các lĩnh vực phổ biến. Tùy thuộc vào tính chất cụ thể của đề tài, có thể phát sinh thêm các loại kiểm định khác như kiểm định Chi bình phương, bảng kết hợp, phân tích phi tham số, hoặc bổ sung các kỹ thuật phân tích mô hình cấu trúc tuyến tính (SEM) trên phần mềm AMOS sau bước EFA (bao gồm phân tích CFA).
Để đảm bảo quy trình nghiên cứu và phân tích phù hợp nhất với đề tài của mình, các bạn luôn nên làm việc chặt chẽ theo sự hướng dẫn và góp ý từ giảng viên hướng dẫn. Việc hiểu rõ từng bước trong quy trình phân tích SPSS không chỉ giúp bạn hoàn thành luận văn mà còn trang bị kỹ năng cần thiết cho các nghiên cứu sau này.